The logic behind advanced maintenance seems straightforward. Invest in condition monitoring, deploy predictive tools, improve asset visibility, gather more operational data, and reactive maintenance should decrease. Firefighting should become less frequent. Teams should spend more time preventing failures than responding to them.
However, research across multiple sources points to a more complicated reality.
McKinsey's research into predictive maintenance found that even organisations with highly qualified analytics teams can struggle to realise the desired impact. A false positive rate of around 10%, excellent by most standards, resulted in 1,000 extra cases per year for one company, wiping out the overall savings from the programme. The volume of signals that predictive tools generate can, in practice, add to the workload rather than reduce it.The tools have evolved since. The dynamic hasn't.
MaintainX surveyed 2,234 maintenance and operations leaders and found that while 64% report using a preventive maintenance programme, half of those teams still dedicate less than 40% of their time to planned work. The gap, their data suggests, is not technological. Labour shortages and skills gaps are among the primary drivers, with 36% pointing to labour shortages as a reason for increased downtime and 28% citing a lack of necessary skills on the team. In other words, teams are stretched too thin to act on what their systems surface.
Two different organisations. Two different diagnoses. But underneath each one is the same underlying condition: detection capability has advanced significantly, while the layer that governs what happens after detection has not kept pace. The result is teams that can see more problems than ever, but lack a consistent mechanism for translating that visibility into the right action at the right time.
As detection has improved, the decision burden has grown with it
Condition monitoring surfaces anomalies. FDD platforms detect and diagnose faults, and many rank them by severity within a given asset. Inspections uncover issues. Building systems report changing conditions continuously. These are genuine advances and they have meaningfully improved how FM teams identify problems.
As these capabilities have matured, however, the volume of signals requiring human evaluation has grown with them. Every alert, every ranked fault, every flagged condition creates a set of operational questions that the detection system itself cannot answer.
How does this issue compare to everything else currently in the queue? What are the downstream consequences of acting now versus scheduling it for next week? Does this require immediate intervention or investigation first? How should the maintenance schedule shift to accommodate it, and what gets deprioritised as a result?
FDD platforms have meaningfully advanced fault prioritisation like detecting issues, diagnosing severity, and in many cases pushing ranked alerts to maintenance teams. But where fault severity ends, the operational decision begins: what this means relative to everything else competing for the team's attention that week is a question FDD was never designed to answer.
This is not a criticism of what these tools do. It is a description of where they stop. And where they stop is precisely where the decision burden lands on maintenance teams who are, as MaintainX's data shows, already stretched by labour constraints and skills gaps.
McKinsey's finding about false positives points to the same dynamic from a different angle. The problem is not that predictive models are inaccurate. The problem is that signals arriving without sufficient operational context to evaluate them quickly become noise. When a team cannot readily determine which alerts reflect genuine operational risk and which do not, every signal demands attention and the overall burden compounds.
The maintenance technologies that exist today are effective at finding problems. The gap is in what happens next.
The missing layer between detection and action
What this points to is not a failure of any individual tool but the absence of something that was never designed into most FM technology stacks to begin with: a layer that sits between detection and execution, holds the full operational context of the facility, and governs how signals are evaluated, prioritised, and acted upon.
Without that layer, every alert becomes a fresh decision that someone has to make manually, often under time pressure, often without complete context. The consistency of the response depends on who is managing the queue, what they know, and what else is demanding their attention at that moment. At scale, across a portfolio of assets and facilities, this variability is where planned maintenance gets crowded out by reactive demands, not because teams are not trying, but because the mechanism for consistent prioritisation does not exist.
With that layer in place, the response to any given signal does not start from scratch. It is evaluated against current operational context, asset criticality, existing maintenance commitments, and the relative priority of everything else in the queue. The decision becomes repeatable and consistent regardless of who is on shift.
This also addresses something that rarely gets discussed directly: the concern that automated systems will make maintenance decisions autonomously. A decision governance layer does not replace human judgment. It ensures that when a human makes the call, they are making it with full operational context rather than a raw signal and limited time. The final decision remains with the maintenance team unless a specific scenario has been configured otherwise.
How Xempla approaches this
Xempla is built on the belief that the value of any detection or monitoring capability is only fully realised through the quality of the decision and the outcome that follows it.
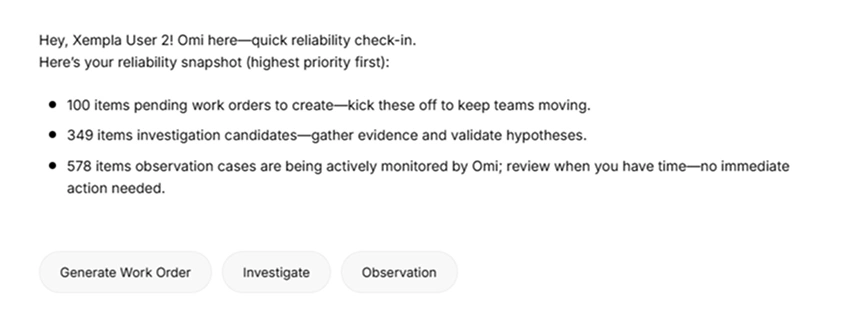
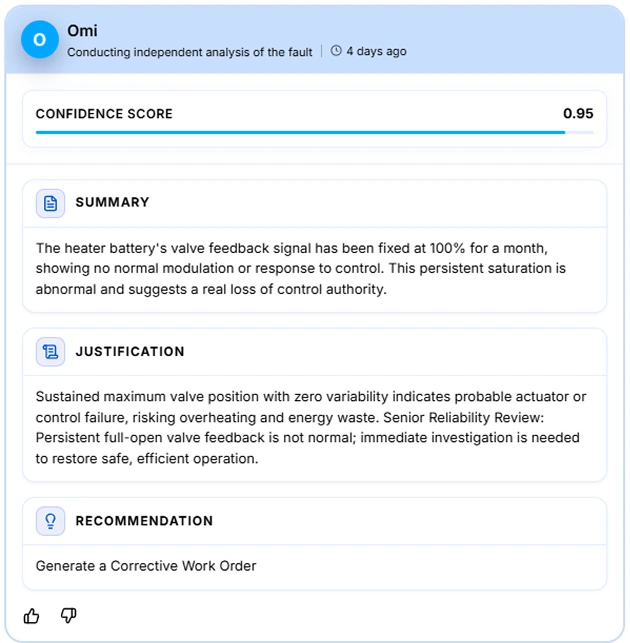
Omi is one of Xempla's AI agents, operating continuously across asset conditions. When Omi detects an anomaly, it does not add another alert to the queue. It evaluates the signal against the operational context of that asset and surfaces a context-rich recommendation: whether the situation warrants a work order now, investigation before any action, or continued observation. The maintenance team receives a reasoned recommendation, not a raw signal asking them to figure out what it means.
Omi routes every signal into one of three clear paths before it reaches the team, so no one is left deciding what to do with a raw alert.
Every Omi recommendation carries the operational context behind it, so the team knows not just what to do but why.
This is directly relevant to what McKinsey's research surfaces. The issue with false positives and signal noise is not that the signals are wrong but that they arrive without the context that makes them actionable. When every signal has to be evaluated from scratch, even a small false positive rate creates a disproportionate burden. Omi applies operational context at the point of detection, before the signal reaches the team, so that human attention is directed toward decisions that genuinely require it.
In practice: A UK-based FM provider managing 8 PFI health and care sites was operating with one reliability engineer governing multiple locations, with reactive demand consistently crowding out planned work. Once governed decision-making was in place, reactive callouts dropped 30-40%. The headcount did not change. What changed was that triage and prioritisation, the work that had been consuming the engineer's capacity, was now handled by the system, freeing the team to focus on planned maintenance rather than constant queue management.
Nira, another of Xempla's agents, works at the planning level. Maintenance schedules are typically built at a point in time and then become increasingly disconnected from operational reality as conditions evolve. What was the right plan last month may no longer reflect current asset priorities. Nira keeps the schedule continuously recalibrated, adjusting based on current asset conditions so that resources follow operational risk rather than fixed intervals. The asset that most needs attention this week is the one that appears at the top of the schedule, not the one that happened to be next in the calendar.
This is where MaintainX's labour constraint finding becomes relevant. When teams are stretched thin, the way limited capacity gets allocated matters enormously. A schedule that continuously reflects current priority means that whatever time and skill is available goes to the highest-value work. The coordination overhead that consumes maintenance capacity when schedules are managed manually decreases because the system is doing that work continuously.
In practice: A solar O&M provider in Australia was rolling trucks based on alerts that had not been properly evaluated for operational context resulting in a first-time fix rate of just 50%. Once triage was automated and decisions were governed before dispatch, first-time fix reached 98% and 100% of triage is now handled by the system. The improvement was not in the detection, the faults were always there. It was in the quality of the decision made before anyone was sent to site.
Together, Omi and Nira create what most FM technology stacks currently leave to chance: a consistent, governed connection between what is detected and what the team does about it, with full operational context present at every step.
What this makes possible over time
The value of decision governance compounds in ways that individual detection tools do not.
At scale, the same decision logic applies across every asset, every site, and every shift. A fault on a critical asset is evaluated the same way whether it surfaces on a Tuesday morning or a Saturday night. The quality of the response does not depend on who happens to be available to judge it.
Because Xempla's agents learn continuously, the system improves over time. Patterns that have been evaluated before inform the next response. The same decision does not need to be made from scratch each time a similar condition recurs. Over time, the decision layer becomes more precisely calibrated to the specific operational context of each facility, which means the quality of recommendations improves as the system accumulates experience.
This is what makes the difference between an FM operation that has advanced maintenance capability and one that has meaningfully reduced firefighting. The detection layer surfaces problems. The decision layer determines what happens next. Both are necessary. For most FM technology stacks today, only one has been built.
What this means in practice
The consequences of a poorly governed decision rarely announce themselves as decision failures. They show up as reactive callouts that could have been scheduled, assets that degraded faster than they should have, and planned maintenance that consistently loses out to urgent demands.
Modern maintenance technologies have made real progress on the detection side of this equation, and that progress matters. The question most FM operations are still working to answer is what a well-governed response to that detection looks like at scale.
Until the space between signal and action is governed consistently, advanced maintenance capability will continue to produce more visibility into operational problems without a corresponding reduction in how often those problems catch teams by surprise. The goal is not better detection in isolation. It is detection followed by the right decision, every time.
FAQs
If we already have predictive maintenance tools, why are we still dealing with so much reactive work?
Because predictive tools solve the detection problem, not the decision problem. They surface faults effectively, but cannot tell your team how a flagged issue compares to everything else in the queue, what the consequences of delaying action are, or how the schedule should shift to accommodate it. Those questions land on teams already stretched by labour constraints. More signals without a consistent way to evaluate them often adds to the workload rather than reducing it.
What is a decision governance layer and how is it different from what FDD or CMMS tools already do?
FDD platforms detect faults and rank them by severity. CMMS tools schedule and track work. A decision governance layer sits on top of those tools, holding the full operational context of a facility and governing how every incoming signal is evaluated against asset criticality, existing commitments, and everything else competing for the team's attention. It does not replace those tools. It closes the gap between what they surface and what the team actually does about it.
Does a decision governance layer take decisions away from the maintenance team?
No. Its role is to ensure that when the team makes a call, they are making it with full operational context rather than a raw signal and limited time. Every recommendation carries the reasoning behind it, so the team knows not just what to do but why. The final decision stays with the people who know the facility. What changes is the quality of information available when they make it.
Why does this matter more as portfolios grow?
Because at scale, variability in decision-making compounds. A single engineer can hold a lot of context across a handful of assets. Across dozens of sites and shifts, that breaks down. A decision governance layer applies the same evaluation logic everywhere, so a fault on a critical system gets the same quality of response regardless of when it surfaces or who is on shift.